

Understanding the Big Picture: Platform Engineer vs DevOps Engineer vs SRE vs Cloud Engineer
Over the last decade, software teams have added a lot of “ops” flavored titles: DevOps Engineer, SRE, Platform Engineer, Cloud Engineer…

They sound similar, they overlap a lot, and job descriptions often mix them up.
This article clears the fog and gives you a big-picture, practical way to understand these four roles:
What each role actually focuses on
How they work together in a modern engineering org
Which one might be the best fit for you
1. Why so many roles in the first place?
Modern systems are:
Cloud-native (AWS/Azure/GCP, Kubernetes, managed DBs, queues, etc.)
Highly distributed (microservices, APIs, event-driven systems)
Always-on (SLAs, SLOs, 24/7 uptime expectations)
Fast-moving (continuous delivery, feature flags, experiments)
No single role can “own everything” anymore. So organizations split responsibilities into complementary specializations:
DevOps focuses on flow of changes from code to production
SRE focuses on reliability and resilience
Platform Engineering focuses on building internal “paved roads”
Cloud Engineering focuses on cloud infrastructure and foundations
Think of it like a city:
Cloud Engineers build the land (networks, base infra, foundations)
Platform Engineers build the roads and utilities (platforms, golden paths, internal tools)
DevOps Engineers help people get their cars from A to B faster (CI/CD, automation, practices)
SREs make sure the city doesn’t go down (reliability, incident response, SLOs)
2. One-line definitions (the TL;DR)
DevOps Engineer
→ Improves how code flows from developer laptop → production, using automation, CI/CD, and good practices.
Site Reliability Engineer (SRE)
→ Software engineer focused on reliability, performance, and incident response, using SLOs and error budgets.
Platform Engineer
→ Builds and maintains an internal developer platform (IDP) and “golden paths” so product teams can ship safely and quickly.
Cloud Engineer
→ Designs, builds, and manages cloud infrastructure (networking, compute, storage, security) as a solid foundation.
3. DevOps Engineer - Owning the Delivery Pipeline
Main focus
Speed + safety of change delivery.
“How do we get features from Git to production quickly, repeatably, and safely?”
Typical responsibilities
Designing and maintaining CI/CD pipelines (GitHub Actions, GitLab CI, Jenkins, etc.)
Automating build, test, and deploy processes
Standardizing branching strategies, environments, and release workflows
Working closely with developers on:
Test automation
Deployment strategies (blue/green, canary, feature flags)
Integrating security into the pipeline (DevSecOps: SAST, DAST, dependency checks)
Writing infra glue: scripts, helper tools, CLI wrappers
Success looks like
Deploys are frequent, predictable, and boring
Rollbacks are easy and tested
Build times are reasonable; feedback loops are fast
Fewer “it works on my machine” issues
Core skills
CI/CD tools, YAML pipelines
Git, branching strategies, release processes
Scripting (Bash, Python, Go, etc.)
Containers (Docker) and basic Kubernetes knowledge
Testing strategies (unit, integration, e2e) and how to plug them into pipelines
4. Site Reliability Engineer (SRE) - Owning Reliability &
Incidents
Main focus
Keeping systems reliable, observable, and resilient
- without killing developer velocity.
Typical responsibilities
Defining SLIs & SLOs (latency, error rate, availability, throughput)
Managing error budgets and negotiating reliability vs. feature speed
Designing and running:
Alerting and on-call rotations
Incident response, postmortems, runbooks
Capacity planning & performance tuning
Building reliability tools: chaos tests, load tests, auto-remediation scripts
Deep observability:
Metrics (Prometheus, CloudWatch, etc.)
Logs (ELK, Loki, etc.)
Traces (Jaeger, OpenTelemetry)
Success looks like
High uptime with fewer “heroic saves”
Alerts are actionable, not noisy
Incidents result in learning and improvements, not blame
SLOs are clear and visible to product/engineering
Core skills
Strong software engineering skills (Python, Go, etc.)
Observability stacks: metrics, logs, traces
Incident management and root-cause analysis
Distributed systems concepts (timeouts, retries, backpressure, CAP trade-offs)
Reliability patterns (circuit breakers, bulkheads, graceful degradation)
5. Platform Engineer -Owning the Internal Developer Platform
Main focus
Developer experience and standardized infrastructure.
“Give product teams a paved road so they can ship without reinventing the wheel.”
Typical responsibilities
Designing & operating an Internal Developer Platform (IDP):
Self-service environments
App templates / scaffolds
Standardized CI/CD pipelines
Providing golden paths:
“This is how you deploy a microservice”
“This is how you add a queue, a DB, or monitoring”
Abstracting cloud/Kubernetes complexity behind:
Portals (Backstage, custom UIs)
CLIs, operators, Helm charts
Governance:
Standardizing logging, metrics, security baselines, cost controls
RBAC, policies, guardrails
Success looks like
Product teams can self-serve infra & deployments
Fewer one-off snowflake setups
Onboarding new developers is fast (“follow the platform path”)
Less time spent on repetitive infra tasks, more time spent on features
Core skills
Multi-disciplinary: cloud, Kubernetes, CI/CD, security, observability
Strong system design and automation mindset
Building tools/portals (TypeScript, Go, Python, APIs)
Understanding developer workflows and pain points
Knowledge of platform tooling (Backstage, Crossplane, Argo CD, etc.)
6. Cloud Engineer - Owning the Cloud Foundations
Main focus
Designing and managing secure, scalable, cost-effective cloud infrastructure.
Typical responsibilities
Designing VPCs, subnets, routing, VPNs, and peering
Managing IAM: roles, policies, least-privilege access
Provisioning and supporting:
Compute (EC2, VM Scale Sets, GKE/EKS/AKS nodes)
Databases (RDS, Cloud SQL, CosmosDB, etc.)
Storage (S3, Blob, GCS)
Messaging (SQS, Pub/Sub, EventBridge, Kafka)
Implementing Infrastructure as Code (Terraform, CloudFormation, Pulumi)
Security baselines: encryption, security groups, WAF, key management (KMS)
Cost optimization and right-sizing resources
Success looks like
Cloud environment is secure by default
Infra is reproducible via IaC, not manual clicks
Costs are monitored and predictable
Scaling is smooth; no surprises under load
Core skills
Deep knowledge of at least one cloud provider (AWS/Azure/GCP)
Networking fundamentals (CIDR, routing, DNS, TLS, VPNs)
Terraform / other IaC tooling
Cloud security best practices
Basic Linux, containers, and automation scripting
7. How they work together in a real product lifecycle
Imagine a new microservice is being built.
Cloud Engineer
Has already set up the base networking, IAM, and shared services (databases, queues, secrets manager, etc.)
Provides Terraform modules or cloud blueprints to use.
Platform Engineer
Provides a service template:
Standard Docker/K8s config
Pre-wired logging & metrics
Default CI/CD pipeline config
Offers a portal/self-service to request environments and resources.
DevOps Engineer
Fine-tunes the CI/CD pipeline for this service:
Runs tests
Builds image
Deploys to staging/prod
Adds security checks, quality gates, and rollback strategies.
SRE
Works with the team to define SLIs/SLOs for the service
Sets up dashboards, alerts, and runbooks
Helps run load tests and tune performance before big launches.
They are not competing roles
- they’re different vantage points on the same mission:
Ship features fast, safely, reliably, and sustainably on the cloud.
8. Role comparison
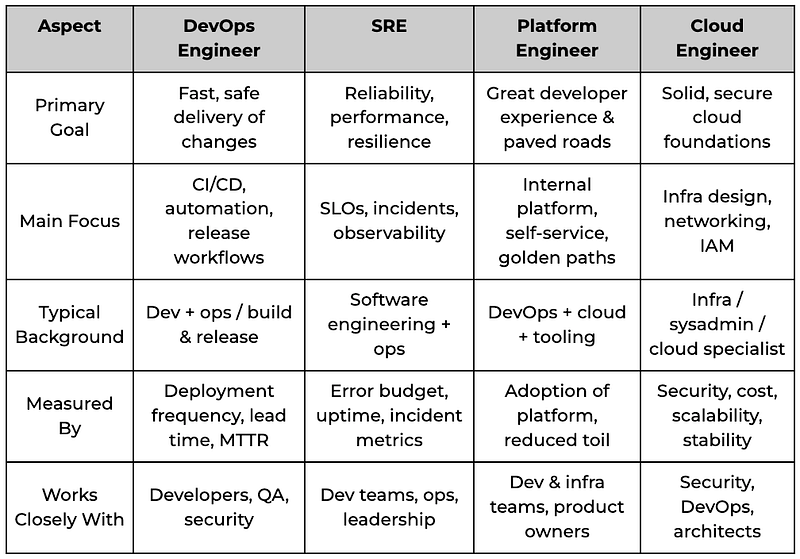
9. Which path is right for you?
A few quick heuristics:
- You enjoy CI/CD, automation, and “making releases painless”
→ You’ll likely enjoy DevOps Engineer roles.
- You like debugging complex incidents, reading metrics, and improving resilience
→ SRE might be your sweet spot.
- You like designing systems for other engineers, building tools & platforms they use
→ Aim for Platform Engineer.
- You love cloud architectures, networking, IAM, and IaC
→ Cloud Engineer fits you well.
In reality, careers aren’t rigid:
Many engineers start as Cloud/DevOps and grow into Platform Engineering.
Some backend engineers move into SRE because they enjoy reliability and infra.
Titles vary a lot across companies; what matters is what you actually do day-to-day.
10. Final thoughts
Instead of asking “Which title is better?”, ask:
“Where in the lifecycle do I want to have the most impact?”
On how code moves → DevOps
On how reliable it runs → SRE
On how teams consume infra → Platform
On what infra exists underneath → Cloud
All four roles are part of the same ecosystem, and the best engineers can speak the language of each even if they specialize in one.



